
参考资料:https://0xinfection.github.io/reversing/
内存
内存以字节为单位。一个字节是8位。两个字节称为一个字,两个字称为双字,即四个字节(32 位),四字称为八个字节(64 位)。
0xffffd040 是 4 个字节并且是一个双字。每个十六进制数字都是 4 位长,也称为半字节。在 0xffffd040 中,如果我们查看 40(十六进制),我们会看到它是一个字节长或 8 位长。如果我们看一下 d040,我们有两个字节或一个字的长度。最后,ffffd040 是一个双字或 4 个字节长度,即 32 位长。地址开头的 0x 只是表明它是一个十六进制值。
x86基本架构
基本架构由CPU、存储器和I/O设备组成,它们都通过系统总线连接。
CPU由4部分组成,分别是:
控制单元 - 从 CPU 检索和解码指令,然后在内存中存储和检索指令。
执行单元 - 执行获取和检索指令的地方。
寄存器——用于临时数据存储的内部CPU存储位置。
Flags - 指示执行发生时的事件。
32 位 CPU 首先从内存中的特定地址获取双字(4 字节或 32 位长度),然后从内存中读取并加载到 CPU 中。此时,CPU 查看双字内位的二进制模式,并开始执行所获取的机器指令指示它执行的过程。
当一条指令执行完成后,CPU会进入内存并按顺序取出下一条机器指令。 CPU 有一个寄存器,我们将在以后的教程中讨论寄存器,称为 EIP 或指令指针,其中包含要从内存中获取并执行的下一条指令的地址。
我们可以立即看到,如果我们控制 EIP 的流程,我们就可以更改程序来执行它不打算执行的操作。这是恶意软件运行的一种流行技术。
整个获取和执行过程与系统时钟相关,系统时钟是一个以精确的时间间隔发出方波脉冲的振荡器。
寄存器
通用寄存器
通用寄存器可用于保存任何类型的数据,其中一些数据已获得程序中使用的特定用途。让我们回顾一下 IA-32 架构中的 8 个通用寄存器。
EAX:用于算术计算的主寄存器。也称为累加器,因为它保存算术运算的结果和函数返回值。
EBX:基址寄存器。指向 DS 段中数据的指针。用于存放程序的基地址。
ECX:计数器寄存器通常用于保存表示进程重复次数的值。用于循环和字符串操作。
EDX:通用寄存器。另外用于 I/O 操作。此外还将把 EAX 扩展到 64 位。
ESI:源索引寄存器。 DS 寄存器指向的段中数据的指针。用作字符串和数组操作中的偏移地址。它保存从何处读取数据的地址。
EDI:目标索引寄存器。指向 ES 寄存器所指向的段中的数据(或目标)的指针。用作字符串和数组操作中的偏移地址。它保存了所有字符串操作的隐含写入地址。
EBP:基址指针。指向堆栈上数据的指针(在 SS 段中)。它指向当前堆栈帧的底部。它用于引用局部变量。
ESP:堆栈指针(在 SS 段中)。它指向当前堆栈帧的顶部。它用于引用局部变量。
上述每个寄存器的长度都是 32 位或 4 个字节。 EAX、EBX、ECX 和 EDX 寄存器的每个低 2 字节都可以由 AX 引用,然后按名称 AH、BH、CH 和 DH(高字节)和 AL、BL、CL 和 DL(低字节)细分每个都是 1 字节。
此外,ESI、EDI、EBP 和 ESP 可以通过其 16 位等效项 SI、DI、BP、SP 来引用。
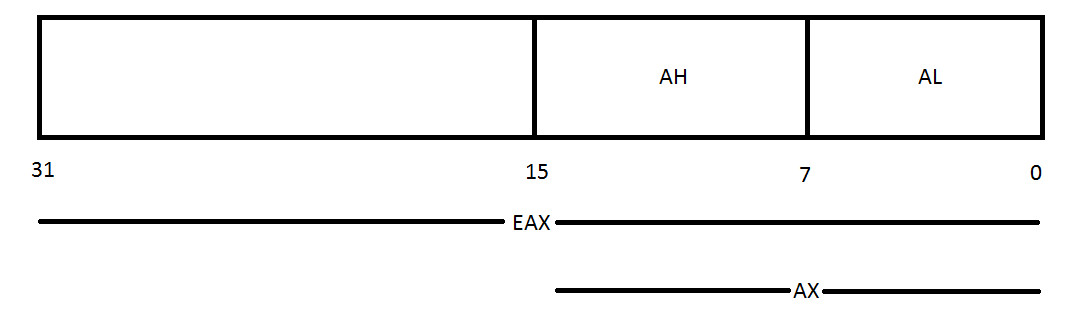
EAX将以AX作为其16位段,然后您可以将AX进一步细分为低8位的AL和高8位的AH。对于 EBX、ECX 和 EDX 也是如此。 EBX 将以 BX 作为其 16 位段,然后您可以将 BX 进一步细分为低 8 位的 BL 和高 8 位的 BH。 ECX将以CX作为其16位段,然后您可以将CX进一步细分为低8位的CL和高8位的CH。 EDX 将以 DX 作为其 16 位段,然后您可以将 DX 进一步细分为低 8 位的 DL 和高 8 位的 DH。
段寄存器
段寄存器专门用于引用内存位置,段寄存器共有 6 个,分别如下:
CS:代码段寄存器存储用于数据访问的代码段(.text 段)的基址位置。
DS:数据段寄存器存储用于数据访问的变量(.data 段)的默认位置。
ES:额外的段寄存器,在字符串操作期间使用。
SS:堆栈段寄存器存储堆栈段的基址,在隐式使用堆栈指针或显式使用基指针时使用。
FS:额外段寄存器。
GS:额外段寄存器。
每个段寄存器都是 16 位,包含指向内存特定段开头的指针。 CS寄存器包含指向内存中代码段的指针。代码段是指令代码在内存中存储的地方。处理器基于CS寄存器值和指令指针(EIP)寄存器中包含的偏移值从存储器检索指令代码。请记住,没有程序可以显式加载或更改 CS 寄存器。当程序被分配内存空间时,处理器会分配其值。
DS、ES、FS和GS段寄存器均用于指向数据段。四个单独的数据段中的每一个都帮助程序分离数据元素以确保它们不重叠。该程序使用段的适当指针值加载数据段寄存器,然后使用偏移值引用各个内存位置。
堆栈段寄存器(SS)用于指向堆栈段。堆栈包含传递给程序内的函数和过程的数据值。
段寄存器被视为操作系统的一部分,在几乎所有情况下都不能直接读取或更改。在保护模式平面模型(32 位 x86 架构)下工作时,您的程序运行并接收 4GB 地址空间,任何 32 位寄存器都可以在其中寻址 40 亿个内存位置中的任何一个,由操作系统定义的受保护区域除外。物理内存可能大于 4GB,但 32 位寄存器只能表示 4,294,967,296 个不同的位置。如果您的计算机内存超过 4GB,操作系统必须在内存中安排一个 4GB 区域,并且您的程序将仅限于该新区域。该任务由段寄存器完成,操作系统对此进行密切控制。
指令指针寄存器
EIP 寄存器的指令指针寄存器是您在任何逆向工程中要处理的最重要的寄存器。 EIP 跟踪下一个要执行的指令代码。 EIP指向下一条要执行的指令。如果更改该指针以跳转到代码中的另一个区域,就可以完全控制该程序。
控制寄存器
五个控制寄存器,用于确定CPU的工作模式和当前执行任务的特性。各个控制寄存器如下:
CR0:控制处理器的工作模式和各种状态的系统标志。
CR1:(当前未实现)
CR2:内存缺页信息。
CR3:内存页目录信息。
CR4:启用处理器功能并指示处理器功能的标志。
每个控制寄存器中的值不能直接访问,但是控制寄存器中的数据可以移动到通用寄存器之一,一旦数据位于通用寄存器中,程序就可以检查该寄存器结合当前运行的任务来确定处理器的运行状态。
如果需要更改控制寄存器标志值,可以对通用寄存器中的数据进行更改,然后移至控制寄存器。
普通应用程序通常不会修改控制寄存器条目,但它们可能会查询标志值以确定当前运行该程序的主机处理器芯片的功能。
标志(Flags)
标志有助于控制、检查和验证程序执行,并且是一种确定处理器执行的每个操作是否成功的机制。
32位情况下,包含一组状态,控制和系统标志的单个32位寄存器。该寄存器称为Eflags寄存器,因为它包含32位映射以表示特定信息标志的信息。
标志分为状态标志,控制标志和系统标志。
状态标志
CF:进位标志:当无符号整数值的数学运算生成最高有效位的进位或借位时,设置进位标志。这是数学运算涉及的寄存器的溢出情况。发生这种情况时,寄存器中的剩余数据不是数学运算的正确答案。
PF:奇偶校验标志:奇偶校验标志用于指示由于寄存器中的数学运算而导致的数据损坏。检查时,如果结果中 1 的总数为偶数,则设置奇偶校验标志;如果结果中 1 的总数为奇数,则清除奇偶校验标志。当检查奇偶标志时,应用程序可以确定自操作以来寄存器是否已损坏。
AF:调整标志:调整标志在二进制编码十进制数学运算中使用,如果从用于计算的寄存器的第3位发生进位或借位操作,则设置该标志。
ZF:零标志:如果操作的结果为零,则设置零标志。
SF:符号标志:符号标志位被设置为结果的最高有效位(即符号位),用于指示结果是正数还是负数。
OF:溢出标志:溢出标志在有符号整数运算中使用,当一个正值太大或一个负值太小以至于无法被寄存器表示时使用溢出标志。
控制标志
控制标志用于控制处理器中的特定行为。 DF 标志是方向标志,用于控制处理器处理字符串的方式。设置时,字符串指令自动减小内存地址以获取字符串中的下一个字节。清除后,字符串指令会自动增加内存地址以获取字符串中的下一个字节。
系统标志
系统标志用于控制OS级操作,这些操作绝不应通过任何相应的程序或应用程序修改。
TF :陷阱标志:设置陷阱标志以启用单步模式,并且在该模式下,处理器一次仅执行一个指令代码,等待信号来执行下一条指令。这在调试时是必不可少的。
IF:中断启用标志:中断启用标志控制处理器如何响应从外部来源收到的信号。
IOPL :i/o特权级别标志:I/O特权字段表示当前正在运行的任务的输入/输出权限级别,并定义了输入/输出地址空间的访问级别,该级别必须小于或等于访问相应地址空间所需的访问级别。在其不小于或者在满足所需访问级别的情况下,任何访问地址空间的请求都将被拒绝。
NT :嵌套任务标志:嵌套任务标志控制当前运行的任务是否与先前执行的任务关联,用于链接被中断和调用的任务。
RF :恢复标志:恢复标志控制处理器在调试模式下对异常的响应方式。
VM:virtual-8086 模式标志:表示处理器是否以virtual-8086模式运行,而不是受保护或真实模式。
AC :对齐检查标志:对齐检查标志与CR0控制寄存器中的AM位结合使用,以启用内存引用的对齐检查。
VIF:虚拟中断标志:虚拟中断标志在处理器以虚拟模式运行时复制 IF 标志。
VIP:虚拟中断挂起标志:虚拟中断挂起标志在处理器以虚拟模式运行时用于指示有中断挂起。
ID:识别标志:ID 标志指示处理器是否支持 CPUID 指令。
堆栈
栈
当程序开始执行时,会为程序留出一段连续的内存,称为堆栈。
堆栈指针是包含堆栈顶部的寄存器。堆栈指针包含最小地址,例如 0x00001000,这样任何小于 0x00001000 的地址都被视为垃圾,任何大于 0x00001000 的地址都被视为有效。
上面的地址是随机的,并不是绝对的,您可以在不同的程序中找到堆栈指针,因为它会有所不同。
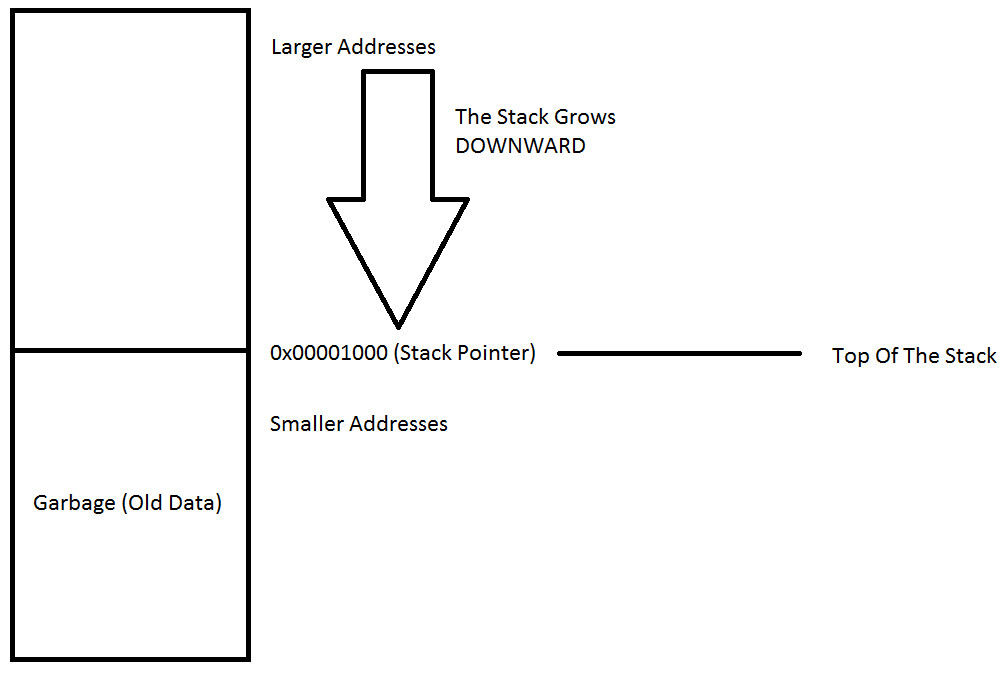 栈底是栈的最大有效地址,位于内存模型的较大地址区域或顶部。堆栈限制是堆栈的最小有效地址。如果堆栈指针变得小于此值,则会出现堆栈溢出,这可能会损坏程序,从而使攻击者能够控制系统。
栈底是栈的最大有效地址,位于内存模型的较大地址区域或顶部。堆栈限制是堆栈的最小有效地址。如果堆栈指针变得小于此值,则会出现堆栈溢出,这可能会损坏程序,从而使攻击者能够控制系统。
栈有两种操作:push和pop。
通过将栈指针设置为较小的值,可以压入一个或多个寄存器。通常通过将栈顶地址减去要压入的寄存器的数量的四倍的值,然后将这些寄存器的内容复制到栈上。
通过将数据从栈复制到寄存器来弹出一个或多个寄存器,然后把栈顶地址加上要弹出的寄存器数量的四倍的值。
之所以是4倍是因为1字节为8位,32位寄存器要占用4字节长度。
堆栈是一个特殊的内存区域,用于存储包括 main 在内的每个函数创建的临时变量。堆栈是一种后进先出的数据结构,由CPU密切管理和优化。每次函数声明一个新变量时,它都会被压入堆栈。每次函数存在时,该函数压入堆栈的所有变量都会被释放或删除。一旦堆栈变量被释放,该内存区域就可用于其他堆栈变量。
使用堆栈存储变量的优点是可以为您管理内存。您不必手动分配内存或手动释放内存。 CPU 非常高效且快速地管理和组织堆栈内存。
重要的是您要了解,当函数退出时,其所有变量都会从堆栈中弹出并永远丢失。堆栈变量是局部的。当函数压入和弹出局部变量时,堆栈会增长和缩小。
堆
堆是计算机内存的一个区域,不会自动为您管理,也不受 CPU 的严格管理。它是一个自由浮动的内存区域,比栈分配的内存要大。
要在堆上分配内存,您必须使用malloc()或calloc(),这是内置的C函数。一旦在堆上分配了内存,您需要负责使用free()释放它,以在不再需要时解除对该内存的分配。
如果您不执行此步骤,您的程序将出现所谓的内存泄漏。也就是说,堆上的内存仍将被保留,并且无法供其他需要它的进程使用。
与栈不同,堆对变量大小没有大小限制。唯一限制堆的因素是计算机的物理限制。堆内存的读取和写入速度稍慢,因为必须使用指针来访问堆上的内存。在堆上创建的变量可以由程序中任何位置的任何函数访问。堆变量本质上是全局范围的。堆是从低地址向高地址增长的,这一点也和栈相反。
指令代码处理
CPU 读取存储在内存中的指令代码,因为每个代码集可以包含一个或多个字节的信息,这些信息指导处理器执行非常特定的任务。随着每个指令代码从内存中读取,与指令代码所需的任何数据也被存储和读入内存。
包含指令代码的内存与包含 CPU 使用的数据的字节没有什么不同,特殊指针用于帮助 CPU 跟踪内存数据的位置以及指令代码的存储位置。
每个指令代码必须包含一个操作码,该操作码定义了CPU要执行的基本功能或任务,操作码的长度在1到3个字节之间,并且唯一地定义了所执行的功能。
举一个例子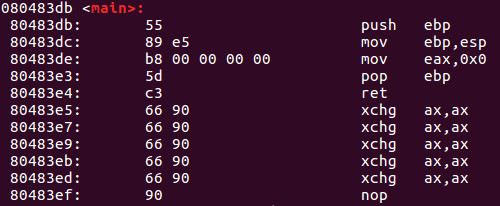 最左边有相应的内存地址。中间是操作码,最后右边是相应的 Intel 语法汇编语言。
最左边有相应的内存地址。中间是操作码,最后右边是相应的 Intel 语法汇编语言。
观察内存80483de,其中的操作码为b8 00 00 00 00,b8操作码对应于mov eax, 0x0,后面的00 00 00 00代表值0的四个字节。IA-32平台使用我们称之为小端记数法,这意味着在从右到左阅读时,较低值字节首先出现,如果指令是mov eax, 0x1,操作码应该是b8 01 00 00 00。
asm程序
每个汇编语言程序都分为三个部分:
.data部分:此部分用于声明初始化数据或常量,因为该数据在运行时不会更改。您可以声明常量值、缓冲区大小、文件名等。
.bss部分:此部分用于声明未初始化的数据或变量。
.text部分:此部分用于实际代码部分,因为它以全局 _start 开头,告诉内核执行位置开始。
对于任何开发来说至关重要的是注释的使用。在 AT&T 语法中,我们使用 # 符号来声明注释,因为编译器将忽略相应行上该符号之后的任何数据。
请记住,汇编语言语句是在每行一个语句中输入的,因为您不必像许多其他语言那样以分号结束该行。语句的结构如下:
[标签] 助记符 [操作数] [注释]
基本指令由两部分组成,第一部分是执行的指令名称或助记符,第二部分是命令的操作数或参数。
实例
移动即时数
#AT&T 版本
.section .data
.section .bss
.lcomm buffer 1
.section .text
.global _start
_start:
nop #用来debug
mov_immediate_data_to_register:
movl $100,%eax #把100移入eax寄存器
movl $0x50,buffer #把0x50写入标签buffer代表的内存位置
exit:
movl $1,%eax #将值1(在这里表示exit系统调用号)移动到寄存器eax中,这个寄存器用于存放系统调用号
movl $0,%ebx #将值0移动到寄存器ebx中,这个寄存器通常用于存放exit系统调用的返回值
int $0x80 #这是一个中断指令,它触发软中断,将控制权转移到内核。在这里,中断号0x80表示调用系统调用。当中断发生时,内核根据eax中的系统调用号执行相应的系统调用,这里是进行程序退出操作。#intel版本
section .data
section .bss
buffer resb 1
section .text
global _start
_start:
nop #用来debug
mov_immediate_data_to_register:
mov eax,100 #把100移入eax寄存器
mov byte[buffer],0x50 #把0x50写入标签buffer代表的内存位置
exit:
mov eax,1 #将值1(在这里表示exit系统调用号)移动到寄存器eax中,这个寄存器用于存放系统调用号
mov ebx,0 #将值0移动到寄存器ebx中,这个寄存器通常用于存放exit系统调用的返回值
int 0x80 #这是一个中断指令,它触发软中断,将控制权转移到内核。在这里,中断号0x80表示调用系统调用。当中断发生时,内核根据eax中的系统调用号执行相应的系统调用,这里是进行程序退出操作。可以看到AT&T和intel语法中源和目标是相反的。
在 Linux 中,有两个不同的内存区域。在任何程序执行的内存最底部,我们都有内核空间,它由调度程序部分和向量表组成。
在任何程序执行的内存最顶部,我们都有用户空间,它由栈、堆以及最后的代码组成,所有这些都可以在下图中说明:
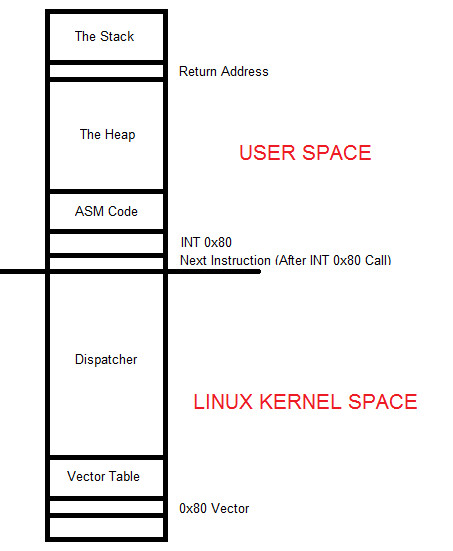
在 x86 汇编中,int 0x80 是一条指令,用于触发 0x80 号中断,从而进入内核态执行系统调用。当发生这个中断时,操作系统会根据寄存器中的值(通常是eax中的系统调用号)执行相应的内核功能,然后将控制返回到用户空间。
用户空间代码执行到 int 0x80 指令时,控制权转移到内核态。
在内核态,操作系统根据 eax 中的系统调用号执行相应的系统调用。
系统调用执行完成后,控制权再次返回到用户空间。
所以当我们加载上面演示的值并调用 INT 0x80 时,用户空间中的下一条指令的地址,ASM 代码部分将被放置到堆栈中的返回地址区域中。这一点至关重要,这样当 INT 0x80 执行其工作时,它可以正确地知道接下来要执行什么指令,以确保正确且顺序的程序执行。

